En SEO llevamos años conviviendo con crawlers clásicos, pero el ecosistema ha cambiado: hoy aparecen rastreadores específicos de IA, cada uno con funciones distintas (entrenamiento, búsqueda/citación o navegación bajo demanda).
Eso significa que el control ya no es un “sí/no” general, sino una decisión granular: qué bots permites, en qué secciones, y con qué objetivo.
En esta guía reunimos los user agent de IA más habituales, explicamos cómo interpretarlos, qué patrones de bloqueo se están extendiendo (incluidos ejemplos de periódicos españoles) y cómo elegir una configuración que favorezca tu estrategia: proteger contenido, gestionar carga del servidor y potenciar tu visibilidad en resultados generados por IA.
Ideas clave que debes conocer
- User agent: Identificador que envía quien hace la petición HTTP (navegador o bot) para decir “quién soy” (Googlebot, Bingbot)
- AI crawler / bot de IA: Robot que solicita URLs para construir índices, recuperar fuentes o recopilar datos (a veces para entrenamiento).
- Robots.txt: Archivo en la raíz del dominio que indica a los robots qué pueden rastrear. Importante: no es un sistema de seguridad ni autorización.
Por qué esto importa (especialmente si quieres visibilidad en IA)
En 2026 ya no compites solo por “rankear en Google”. También compites por:
- Ser citado y enlazado por asistentes (ChatGPT, Perplexity, Claude…),
- Aparecer en respuestas con fuentes
- Que tu marca se asocie a un tema (Brand mentions + entidades).
Para eso, tu web necesita dos cosas:
- Accesibilidad técnica (los bots adecuados pueden entrar).
- Control (los bots que no te interesan, fuera).
Y el punto de control más básico suele ser robots.txt + user agent.
No todos los user agent de IA hacen lo mismo
1) Bots para entrenamiento (dataset / model development)
Los bots para entrenamiento son robots (crawlers) que recorren webs como lo haría un buscador, pero con un objetivo distinto: recopilar contenido para crear o mejorar modelos de IA (por ejemplo, mejorar cómo entienden el lenguaje, resumen, responden, etc.).
Suelen identificarse con un user agent específico y, si tu web lo permite, pueden acceder a tus páginas y leerlas de forma automatizada.
Ejemplos más claros:
- GPTBot (OpenAI): es el crawler que OpenAI documenta para rastrear contenido que puede usarse para entrenar/mejorar modelos.
- Google-Extended es un token que Google ofrece para que los editores controlen si su contenido puede usarse para entrenamiento en Gemini y otros productos de IA. Google indica que no afecta al posicionamiento en Google Search.
2) Bots para búsqueda / descubrimiento / citación (AI search)
- OAI-SearchBot (OpenAI): OpenAI indica que, para que tu contenido pueda incluirse en resúmenes/snippets en ChatGPT, conviene no bloquearlo.
- PerplexityBot: Perplexity documenta que está pensado para surfacing/linking en sus resultados y recomienda permitirlo si quieres aparecer allí.
3) Acceso bajo demanda del usuario (user-triggered)
- ChatGPT-User: Se usa cuando un usuario pide que ChatGPT visite una página (no es crawling automático). En teoría, según la web oficial de OpenAI este bot puede hacer caso o no al archivo robots.txt, pero según nuestras pruebas, hasta el momento impide totalmente que “ChatGPT-User” pueda acceder a información de la web.
Lista práctica de user agent de IA (los más relevantes)
User agent de OpenAI (ChatGPT / OpenAI)
- GPTBot → entrenamiento/mejora de modelos
- OAI-SearchBot → descubrimiento/citación para ChatGPT search
- ChatGPT-User → acceso bajo demanda del usuario
- Google-Extended → controla el uso para entrenamiento en Gemini; no impacta inclusión ni ranking en Google Search
Anthropic (Claude)
- ClaudeBot (y otros) → Anthropic explica que usa robots diferentes para desarrollo, búsqueda y retrieval bajo demanda, y que puedes gestionar preferencias.
Perplexity
- PerplexityBot → bot de búsqueda que enlaza fuentes en Perplexity (no hacen entrenamiento de foundation models según su doc).
Ejemplos reales en España: periódicos que bloquean bots de IA (enero 2026)
Cómo gestiona ABC los user agent de los LLMs
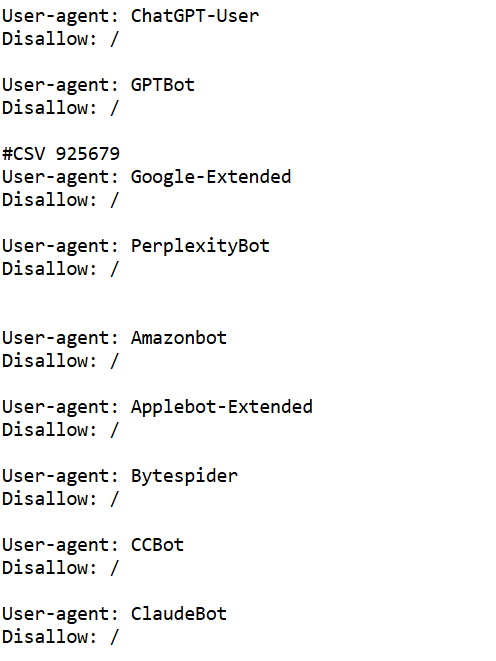
En el robots.txt de ABC observamos un bloqueo total del rastreo para varios user agent asociados a IA y a crawlers automatizados. En la captura aparecen con Disallow: /, entre otros:
- OpenAI: ChatGPT-User, GPTBot, OAI-SearchBot
- Google (IA): Google-Extended
- Perplexity: PerplexityBot
- Anthropic: ClaudeBot
- Otros crawlers/datasets: CCBot (Common Crawl), Applebot-Extended, Bytespider, Amazonbot, ia_archiver
ABC impide que estos bots accedan a cualquier URL del sitio, lo que limita tanto el uso del contenido para IA (incluido entrenamiento) como su posible descubrimiento/citación en experiencias de búsqueda basadas en IA.
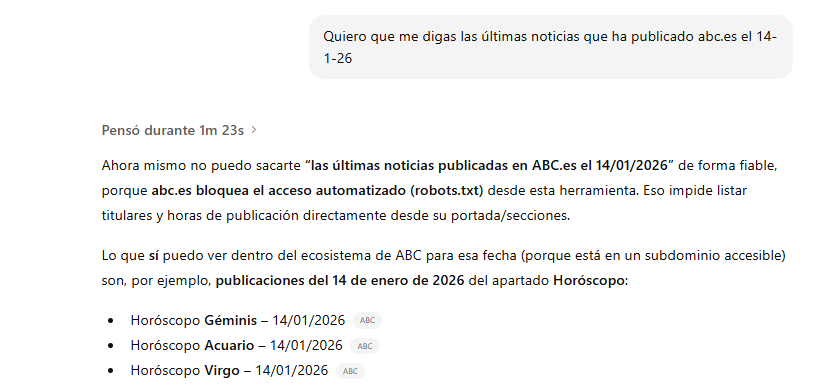
¿Qué pasa cuando pedimos información a ChatGPT sobre ABC?
No es capaz de acceder a la web de ABC.es, por lo que navega por otros subdominios de ABC a los que sí tiene acceso, en este caso a su subdominio de horóscopo (horoscopo.abc.es)
Otros periódicos:
Cómo gestiona La Razón el acceso de los user agent de IA
En este caso solo están bloqueando el user agent de ChatGPT que se encarga de entrenar a su modelo. Por lo que en el conocimiento general de ChatGPT no se incluirá información de La Razón, pero sí que puede acceder en tiempo real para citar su contenido.


Cómo gestiona El País los user agent de los LLMs
En este caso optan por no bloquear ningún user agent de LLMs. Por lo que El País adopta una estrategia abierta frente a los bots de IA: al permitir el acceso a los principales user agent, facilita que sus contenidos puedan ser rastreados para descubrimiento, citación y aparición en experiencias de búsqueda con IA.
Esta postura prioriza el alcance y la visibilidad de marca en el nuevo ecosistema de “motores de respuesta”, aunque también implica aceptar un mayor grado de recolección automatizada del contenido por parte de terceros. En la práctica, es un enfoque opuesto al de medios como ABC, que bloquean de forma total estos rastreadores para limitar usos y controlar la redistribución.
Cómo afecta el bloqueo por robots a la visibilidad en IA
Cuando pedimos noticias de actualidad en España, las fuentes suelen ser las mismas, portales que dan total acceso a los user agent de IA. Después de varias pruebas “El País y Cadena SER” han aparecido siempre como fuente. El periódico La Razón en teoría puede ser rastreado y utilizado como fuente, pero en la práctica no lo ha mencionado a no ser que se lo especifique directamente.

Conclusiones
- Cuanto más acceso das a los bots de IA, más probabilidades tienes de aparecer en respuestas y resultados generados por IA (caso El País).
- Bloqueo total = invisibilidad práctica: si bloqueas los bots de IA (y especialmente los de descubrimiento), es normal que el medio no aparezca ni aunque lo pidas (caso ABC).
- Bloquear solo “entrenamiento” no debería excluirte, pero en la práctica puedes quedar fuera si la IA no puede rastrear/recuperar tu contenido por otras barreras (paywall, restricciones técnicas, ausencia de bots de búsqueda permitidos, etc.). Esto encaja con que La Razón casi no aparezca, salvo mención explícita.
- La decisión clave no es “IA sí o no”, sino qué permites: entrenamiento vs descubrimiento/citación. La estrategia intermedia suele ser bloquear entrenamiento y permitir bots de búsqueda/citación.
- Todavía no hay consenso sobre la “mejor opción”: pesa el temor a perder control/tráfico, la incertidumbre sobre monetización en entornos IA y la falta de métricas estándar. Aun así, la lógica actual es simple: si no te pueden rastrear, difícilmente te pueden recomendar.
- Hay otras estrategias por explorar. Por ejemplo, dar acceso solo a ciertas partes de la web y dejar secciones concretas fuera del radar de los user agent de IA.

 Mar 03, 2026
Mar 03, 2026 



